
前言
在复杂的服务器与应用架构中,为实现对系统运行状态的全面掌控,需要一套覆盖基础设施、中间件、应用服务的完整监控方案,基于 Prometheus 与 Grafana 构建的全栈指标监控体系,通过统一采集、存储、查询与可视化各类运行指标,能够实时监控 CPU、内存、服务性能等关键数据,并支持异常告警与直观图表展示,从而实现全方位、可视化、可预警的系统监控,保障服务稳定可靠运行。
一、拆分所需要用到的工具作用
1.什么叫Prometheus?
a.它就是专门收集各种数据的工具,并且它把这些数据存起来,出问题还能报警
服务器 CPU 多少
内存用了多少
硬盘满没满
网络卡不卡
MySQL 查询慢不慢
接口访问量 QPS
容器崩没崩
应用有没有报错
2.什么叫Grafana
a. 把Prometheus 存数据的 数字 转换为折线图、柱状图、仪表盘
CPU 曲线
内存趋势
接口访问量
系统负载
各种清晰明了的面板
3.全栈指标监控体系
a.一种全方位的监控器,只要你所能用的数据、服务器、应用都可以检测
机器监控
容器监控
数据库监控
应用接口监控
业务指标监控
4.什么叫 Node Exporter
主机数据采集插件
安装在服务器上,帮Prometheus收集主机的CPU、内存、登录等指标
5.什么叫Alertmanager
类似告警通知员
当触发“异常登录”“CPU突增”时,发送告警(此次使用邮件告警)
二、运行逻辑
此时实验整个底层逻辑我们可以想象成一个快递监控系统
我们把Node Exporter想象成一个快递员,它每天定时去服务器 ,抄下 CPU、内存、连接数这些数据,打包成 “快递”,送到指定地点。
Prometheus类似是一个监控系统,它接收快递员送来的数据,然后把数据存起来,再对照我们写的告警规则,检查数据有没有出问题,如果出问题了,立刻通知报警器。
Grafana类似是一个监控屏幕,把 Prometheus 里枯燥的数据,画成折线图、仪表盘,让你一眼看懂快递员送的数据。
alert.rules这个文件类似监控的检查清单,我们写好的规则,比如 “CPU 超过 80% 算异常”“内存超过 85% 算异常”,Prometheus 就照着这个清单一条一条检查。
Alertmanager类似是报警器 + 短信平台,收到 Prometheus 的异常通知后,按照我们设置的方式(比如邮件),给我们发提醒
三、实验前准备
此时实验我准备的是Ubuntu24.04操作系统,并且我们需要root权限,端口是默认的22
IP:172.16.11.52,我使用的是NAT,根据自身情况设置
四、实验目的
掌握 Prometheus + Grafana 全栈监控体系的架构与工作原理
学会部署指标采集组件、监控服务与可视化平台,实现服务器、应用等运行指标的统一采集与存储
能够通过 Grafana 搭建监控看板,实现指标可视化展示,并配置异常告警规则
五、实验步骤
1.环境准备
# 进入root模式
sudo -i
# 替换为清华源
# 备份原有源,防止出错(根据需求,可选!!!!)
cp /etc/apt/sources.list /etc/apt/sources.list.bak
tee /etc/apt/sources.list <<EOF
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-security main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-backports main restricted universe multiverse
EOF
# 更新软件缓存
apt update
# 关闭防火墙
# 临时关闭防火墙
systemctl stop ufw
# 永久关闭防火墙(重启服务器也不会生效)
systemctl disable ufw2. 安装+验证 Node Exporter
Node Exporter类似服务器眼线,作用就是给服务器装“探头”,让它帮我们收集CPU、内存等数据,没有它,后面的监控就没数据
a.操作步骤
# 基础依赖
apt install -y apt-transport-https software-properties-common wget gpg
# 安装 Node Exporter
apt install -y prometheus-node-exporter
# 设置 Node Exporter 开机自启
systemctl enable --now prometheus-node-exporter
# 验证 Node Exporter 是否安装成功
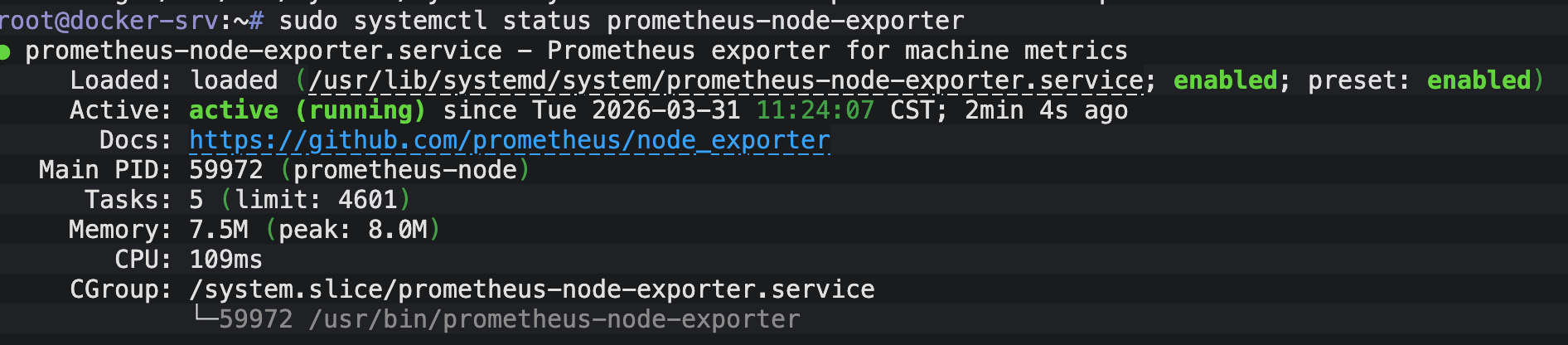
systemctl status prometheus-node-exporterb.结果图
Node Exporter:看到running代表成功
3.安装+配置 Prometheus
Prometheus类似 数据采集员,作用就是让它去“探头”(Node Exporter)那里收集数据、存数据,还能判断是不是出问题了
a.操作命令
# 安装 Prometheus
apt install -y prometheus
# 设置开机自启
systemctl enable --now prometheus
# 配置 Prometheus
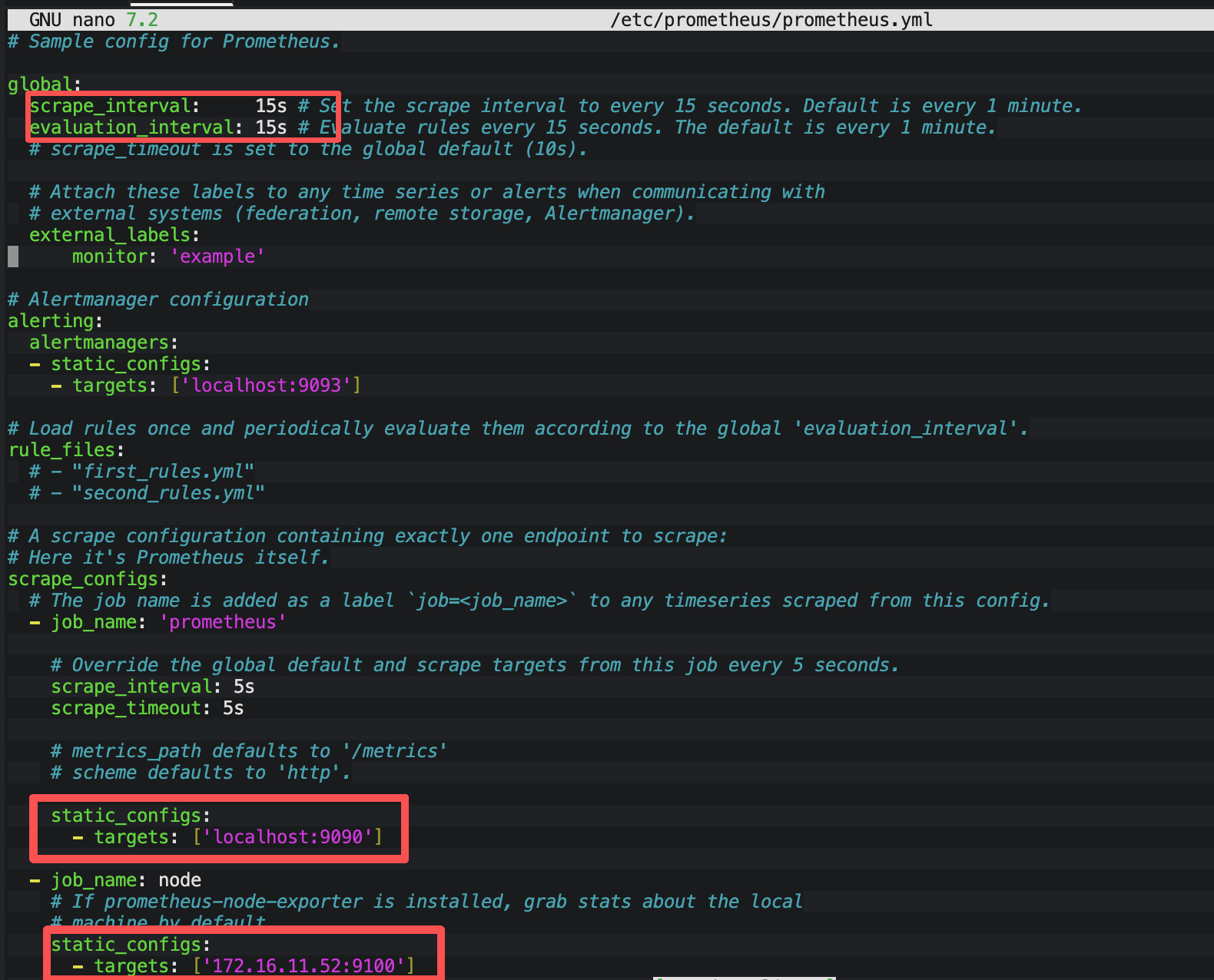
nano /etc/prometheus/prometheus.yml
# 根据以下内容更改
global:
scrape_interval: 15s # 每15秒采集一次数据
scrape_configs:
# 采集虚拟机(主机)数据(Node Exporter)
- job_name: 'node'
static_configs:
- targets: ['172.16.11.52:9100'] # 固定你的虚拟机IP
# 采集Prometheus自身数据(监控自身是否正常运行)
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090'] # 固定值,无需修改
# 重启Prometheus
systemctl restart prometheus
# 验证 Prometheus
systemctl status prometheusb. 结果图
更改的内容
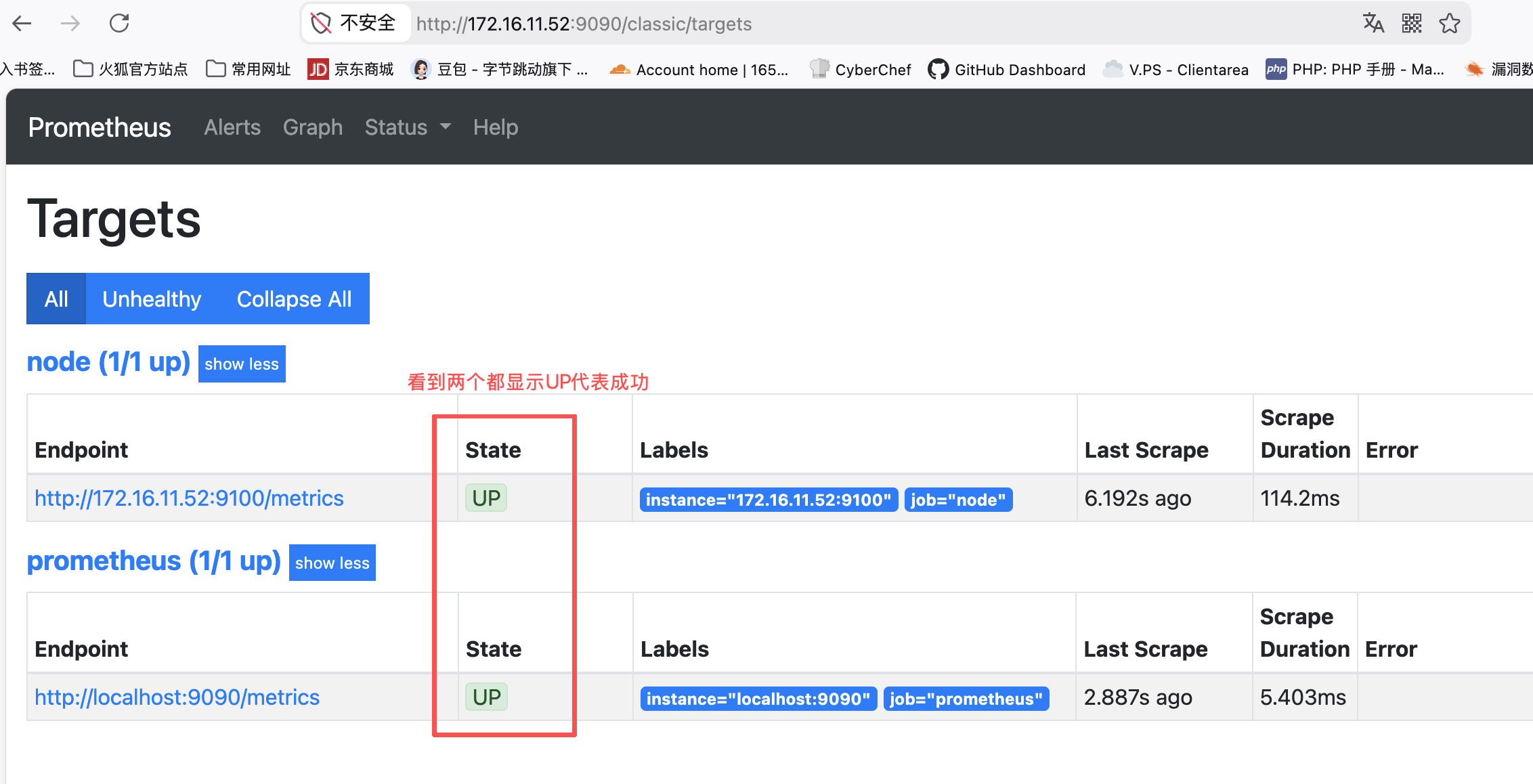
登录浏览器的web页面输入
http://172.16.11.52:9090,能看到Prometheus的web界面,点击顶部Status->Targets,UP就代表成功了这一步的意义就是,采集员能正常从“探头”那里收集数据
4.安装 Grafana
安装“可视化画家”(Grafana)作用:把采集员存的枯燥数字,变成直观的图表,一眼就能看懂服务器状态
a.操作命令
# 导入Grafana密钥
wget -q -O - https://packages.grafana.com/gpg.key | gpg --dearmor | sudo tee /usr/share/keyrings/grafana.gpg
# 添加清华源的Grafana仓库
echo "deb [signed-by=/usr/share/keyrings/grafana.gpg] https://mirrors.tuna.tsinghua.edu.cn/grafana/apt/ stable main" | sudo tee /etc/apt/sources.list.d/grafana.list
# 安装 Grafana
apt update && sudo apt install -y grafana
# 启动 Grafana 并设置开机自启
systemctl enable --now grafana-server
# 验证 Grafana 是否安装成功
systemctl status grafana-serverb.结果图
浏览器访问你的
ip+端口初次登陆的用户和密码都为admin,输入以后会让你改密码
5.配置 Grafana 连接 Prometheus
让“画家”对接“采集员”(Grafana连接Prometheus), 作用:让画家(Grafana)能拿到采集员(Prometheus)存的数据,才能画出监控图表
先保证有
Prometheus这个插件,没有去插件商场下载点击左侧菜单栏 Connection -> 点击 Data Sources -> 点击 Prometheus图标
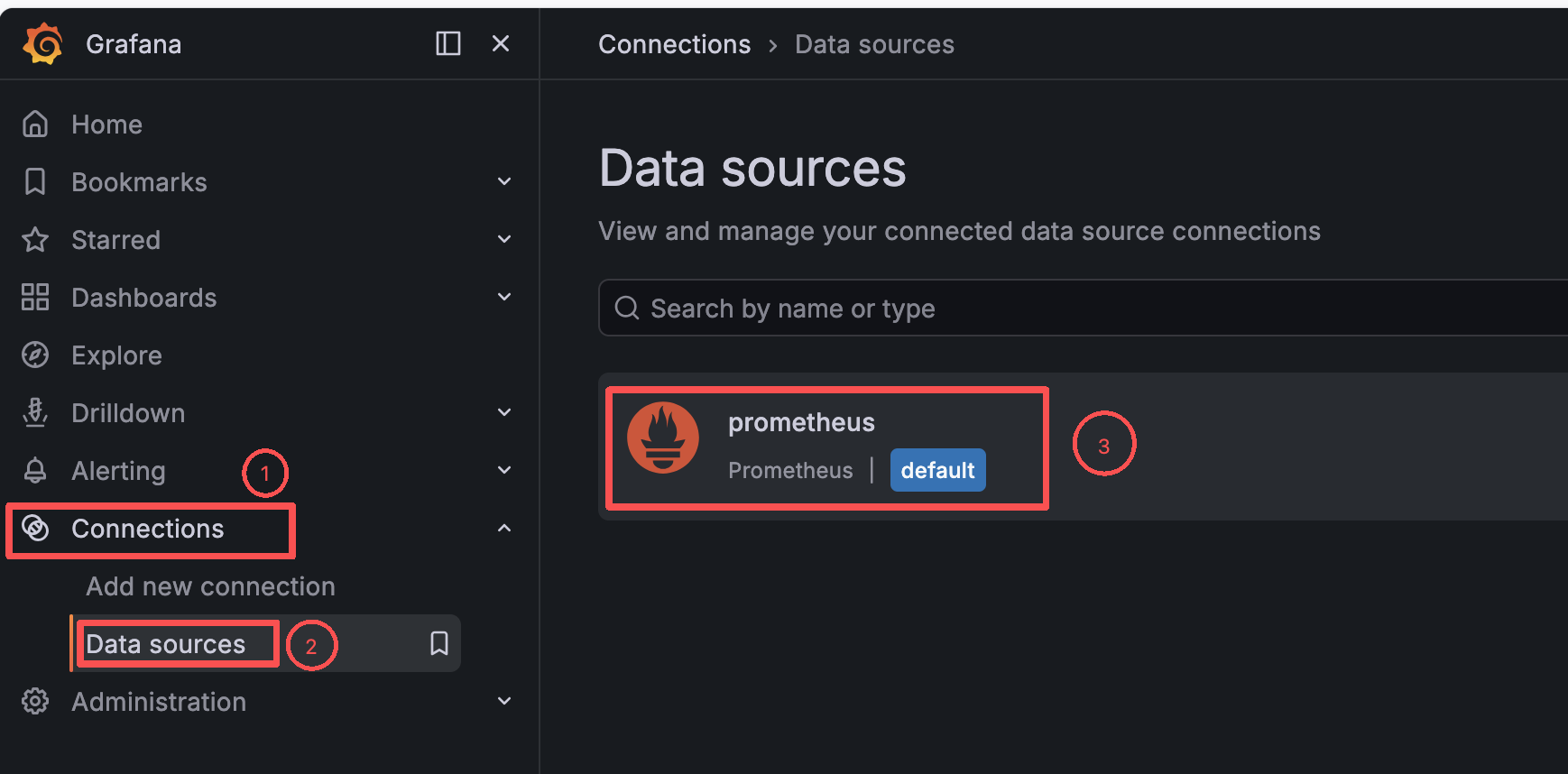
写上URL,然后保存,其他默认不变
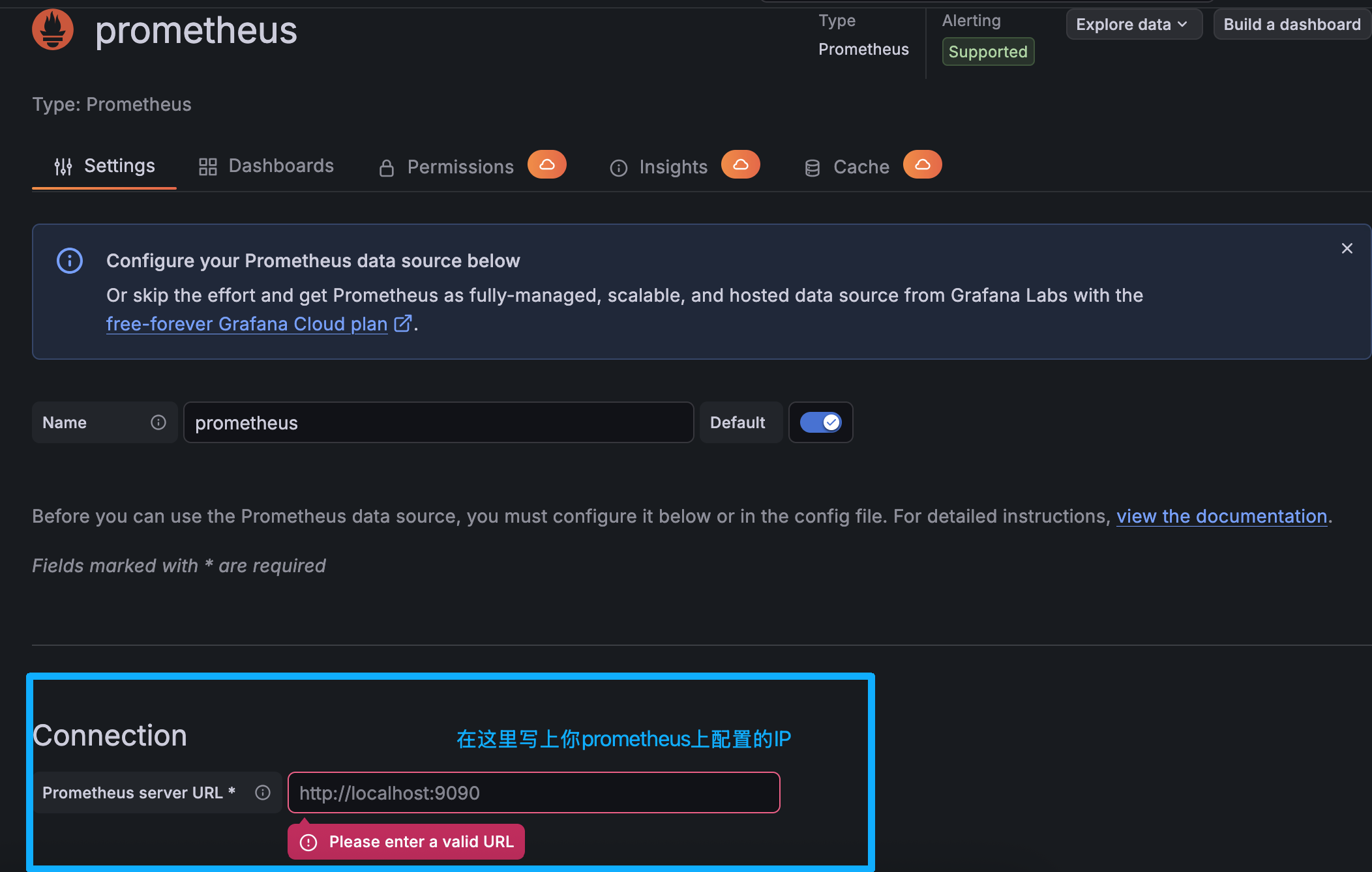
点击页面最下方
Save & Test,出现Successfully queried the Prometheus API,说明连接成功
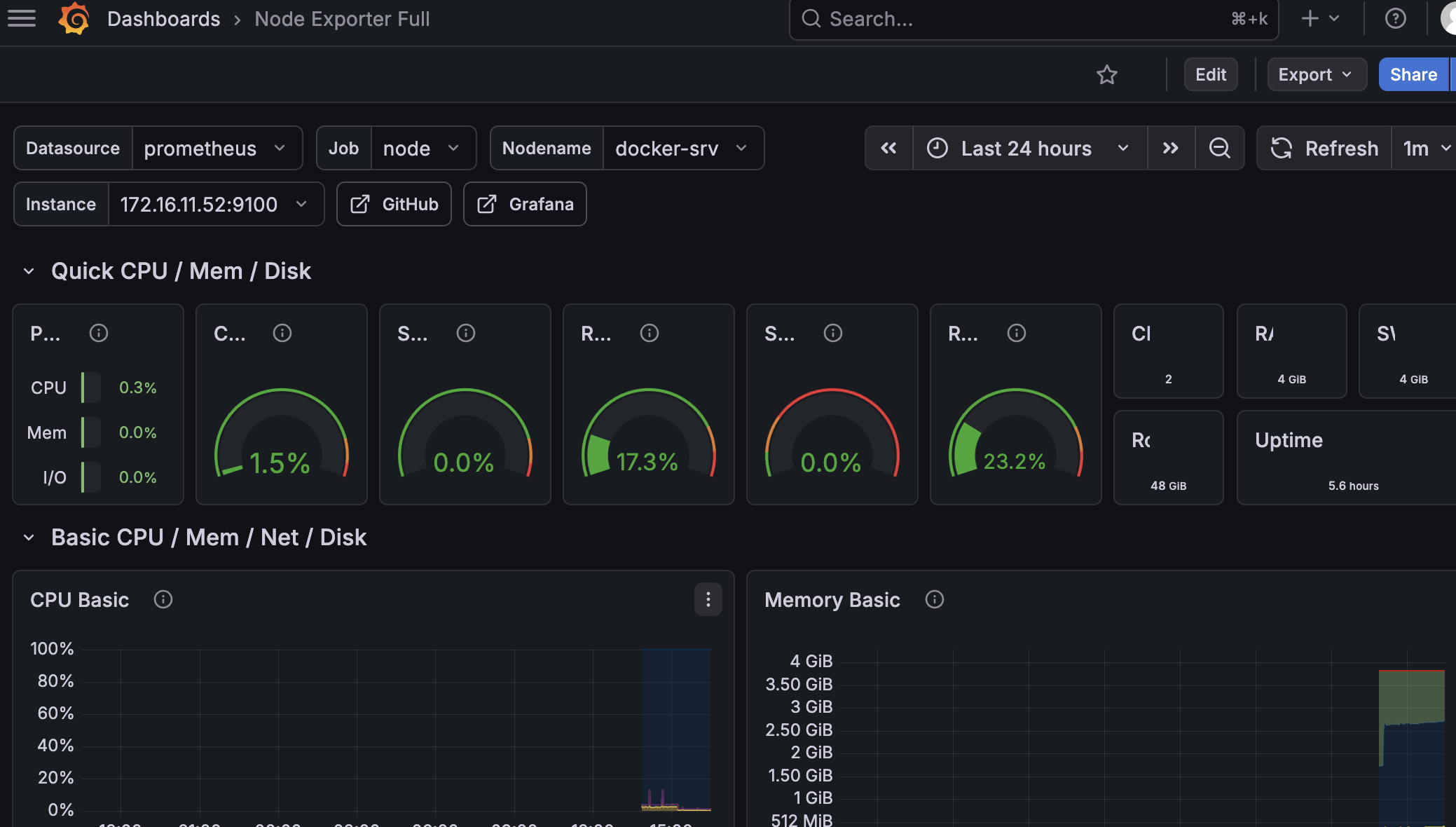
6.导入主机监控面板
导入监控面板(一键生成可视化图表,不用自己画), 这是为了不用自己动手画CPU、内存的图表,官方有现成的模板,一键导入,直接能用
a. 点击左侧菜单栏 Dashboards -> Import
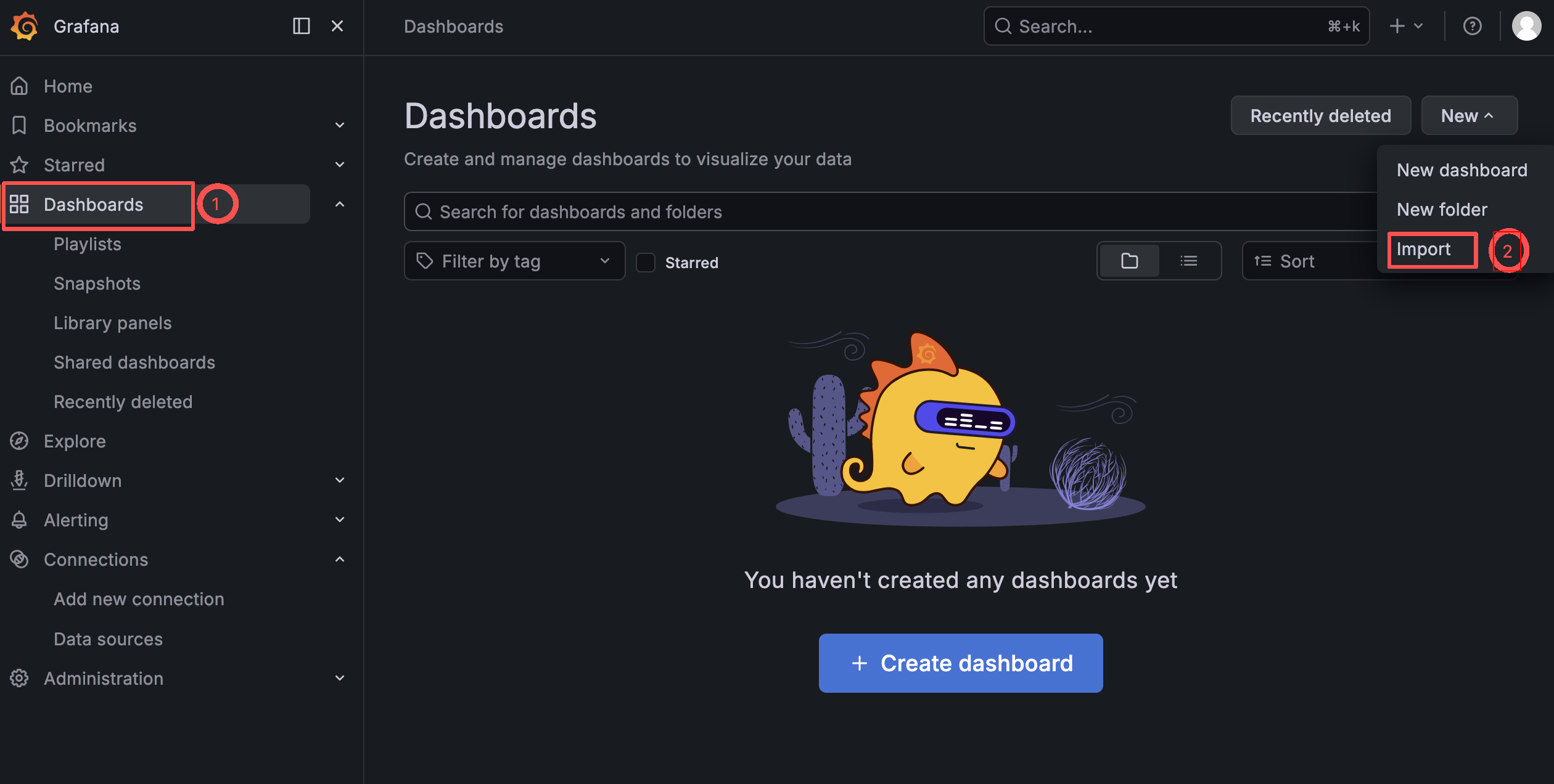
b.输入面板ID:1860(可自行选择),点击 Load
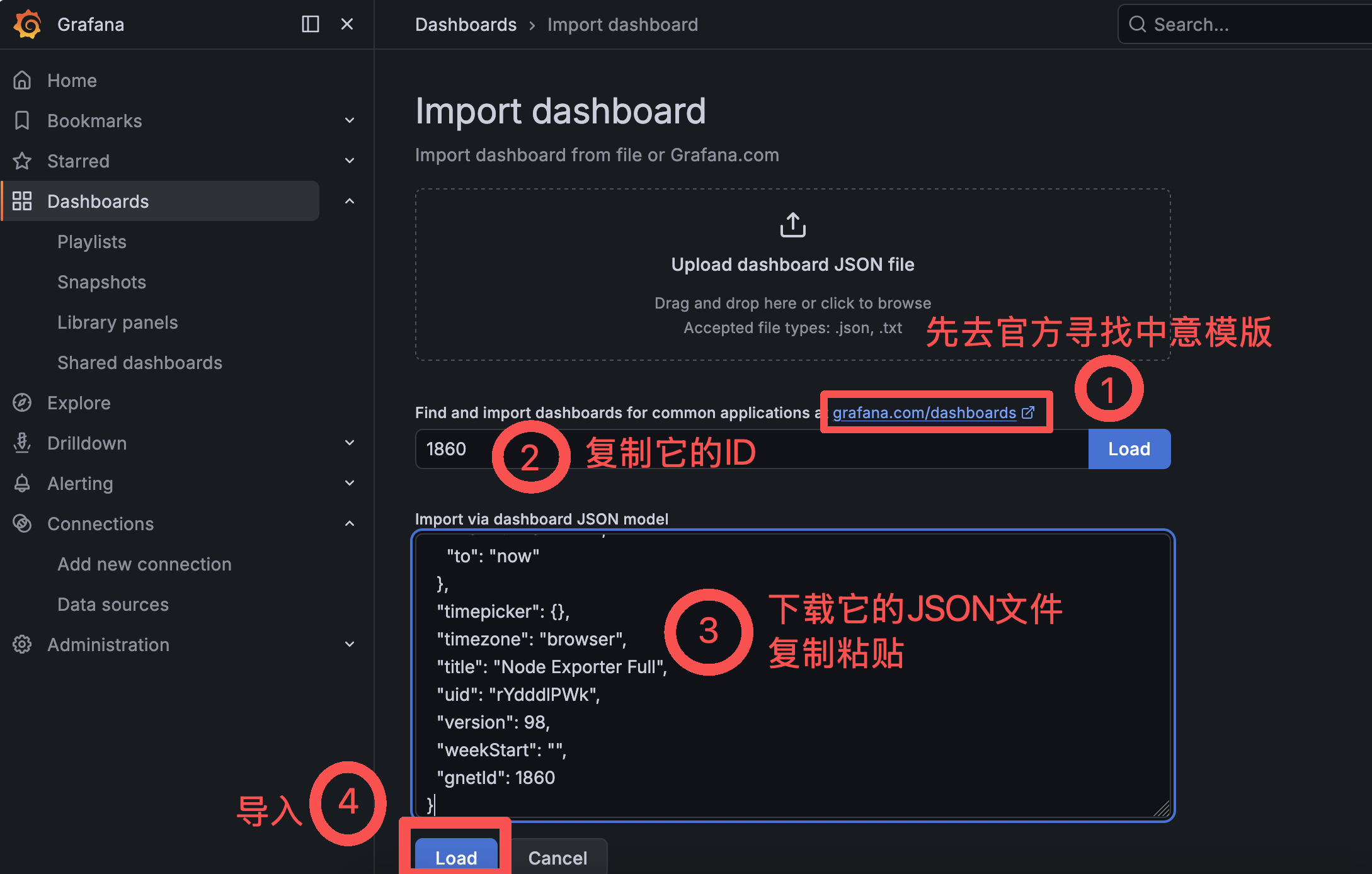
c.点击以后会跳转到,再次倒入就行
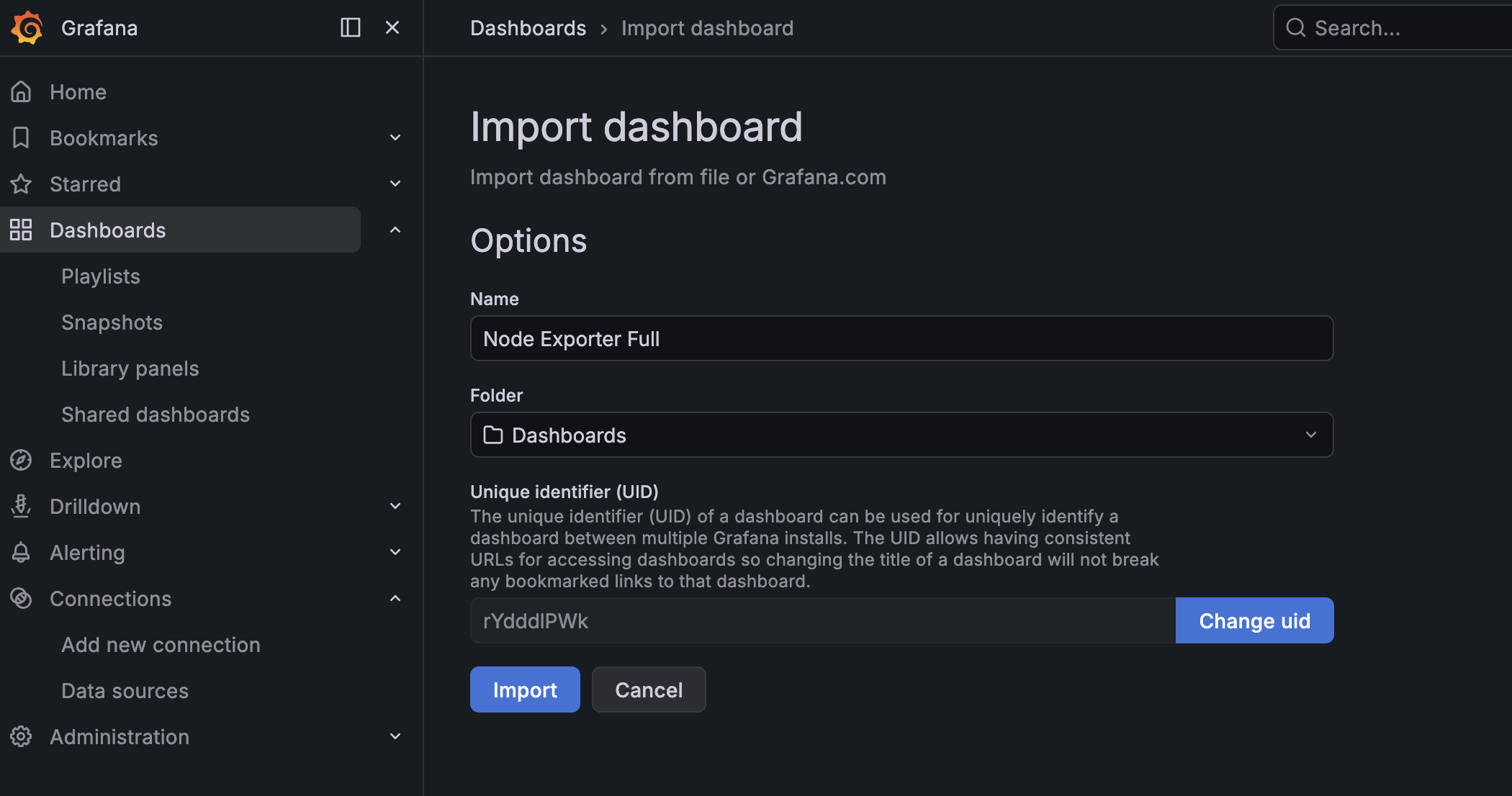
d. 结果图
7.配置告警规则
设置“自动告警”(服务器出问题,自动发邮件提醒)这一步是为了不用24小时盯着监控面板,只要服务器出问题(比如CPU占满、内存不够),就会自动给你发邮件,能实现“无人值守监控”
a.操作命令
邮件警告
# 安装 Alertmanager
apt install -y prometheus-alertmanager
# 设置开机自启
systemctl enable --now prometheus-alertmanager
# 配置 Alertmanager
# 1.获取邮箱授权码(以QQ邮箱为例)
登录QQ邮箱→设置→账户→开启“IMAP/SMTP服务”→获取授权码(保存好,后面要用)
# 2.编辑Alertmanager配置文件
nano /etc/prometheus/alertmanager.yml
# 3.删除原有内容,复制以下内容
global:
resolve_timeout: 5m # 告警恢复后,5分钟内停止通知
route:
group_by: ['alertname'] # 按告警名称分组
group_wait: 10s # 同一组告警,等待10秒再发送(避免频繁告警)
group_interval: 10s # 同一组告警,间隔10秒发送一次
repeat_interval: 1h # 同一告警,每1小时重复发送一次(避免刷屏)
receiver: 'email_notify' # 默认告警接收者
receivers:
- name: 'email_notify'
email_configs:
- to: '你的接收邮箱@qq.com' # 替换成你要收告警的邮箱
from: '你的发送邮箱@qq.com' # 替换成你的QQ邮箱(和授权码对应)
smarthost: 'smtp.qq.com:587' # QQ邮箱SMTP服务器(固定)
auth_username: '你的发送邮箱@qq.com' # 替换成你的QQ邮箱
auth_password: '你的邮箱授权码' # 替换成刚才获取的授权码
require_tls: true # 开启加密(固定)
# 4. 重启Alertmanager
systemctl restart prometheus-alertmanager配置 Prometheus 关联 Alertmanager
nano /etc/prometheus/prometheus.yml
# global 下面,添加以下内容
alerting:
alertmanagers:
- static_configs:
- targets: ['172.16.11.52:9093'] # 固定虚拟机IP,Alertmanager默认端口9093
rule_files:
- "alert.rules" # 告警规则文件(后面创建,固定名称)
# 创建告警规则文件
nano /etc/prometheus/alert.rules
# 配置核心告警规则,复制以下内容,粘贴到alert.rules文件中
groups:
- name: "虚拟机监控告警"
rules:
# CPU使用率告警
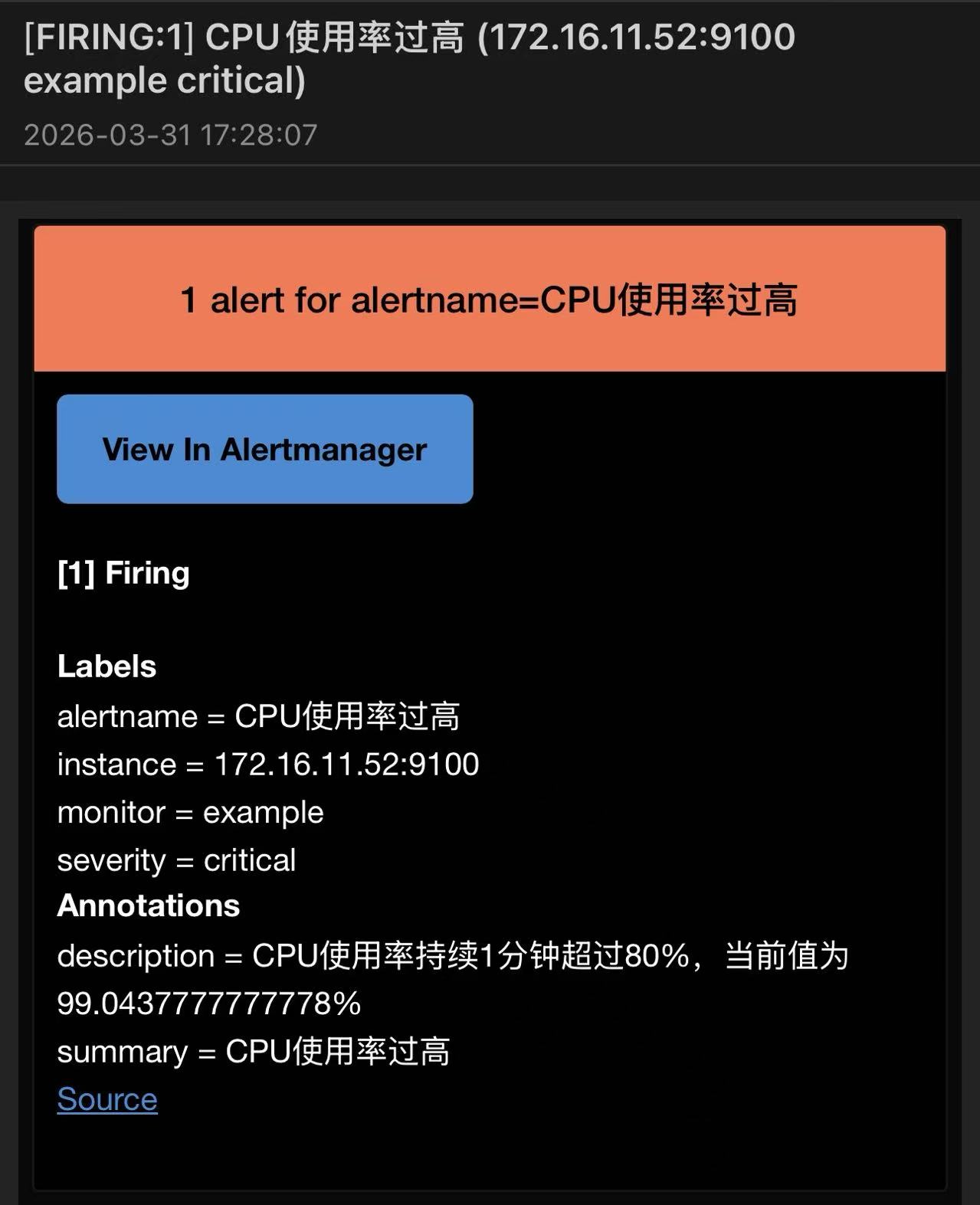
- alert: CPU使用率过高
expr: 100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) > 80
for: 1m
labels:
severity: critical
annotations:
summary: "CPU使用率过高"
description: "CPU使用率持续1分钟超过80%,当前值为 {{ $value }}%"
# 内存使用率告警
- alert: 内存使用率过高
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 85
for: 1m
labels:
severity: warning
annotations:
summary: "内存使用率过高"
description: "内存使用率持续1分钟超过85%,当前值为 {{ $value }}%"
#给文件授权
chown prometheus:prometheus /etc/prometheus/alert.rules
#重启Prometheus
systemctl restart prometheusprometheus.yml里写的rule_files: ["alert.rules"],是告诉 Prometheus:“去读取alert.rules这个文件,里面是我给你的告警规则”。alert.rules里写的 CPU使用率过高 这条规则,是给Prometheus下达的具体指令:“当服务器 CPU 使用率持续 1 分钟超过 80% 时,就把这条告警标记为 Firing(已触发)”
b.结果图
邮件结果:
Prometheus上
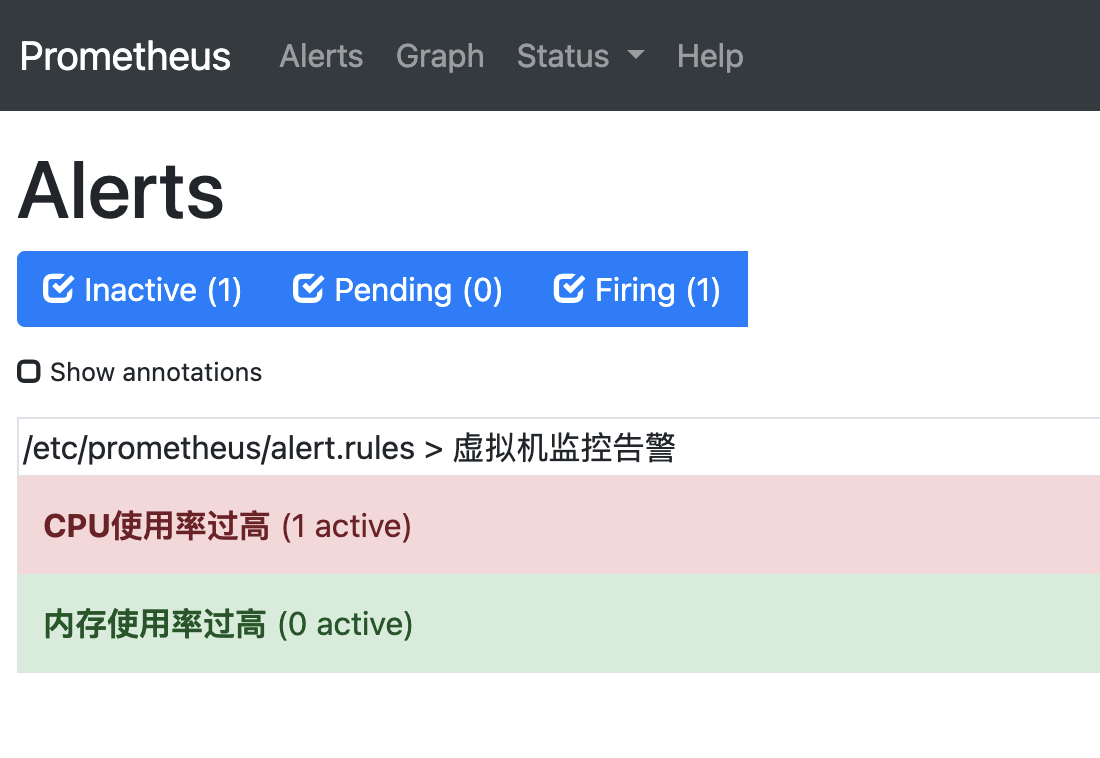
以上图为例 这就是重启 Prometheus 后,会做的两件事:
加载 alert.rules 里的所有规则;
每 15 秒检查一次服务器指标,看看是否满足规则条件。
当条件满足(比如CPU 持续 1 分钟超过 80%),Prometheus 就会:
在 Alerts 页面,把这条告警标记为 红色 Firing;
把不满足条件的 内存使用率过高 标记为 绿色 Inactive
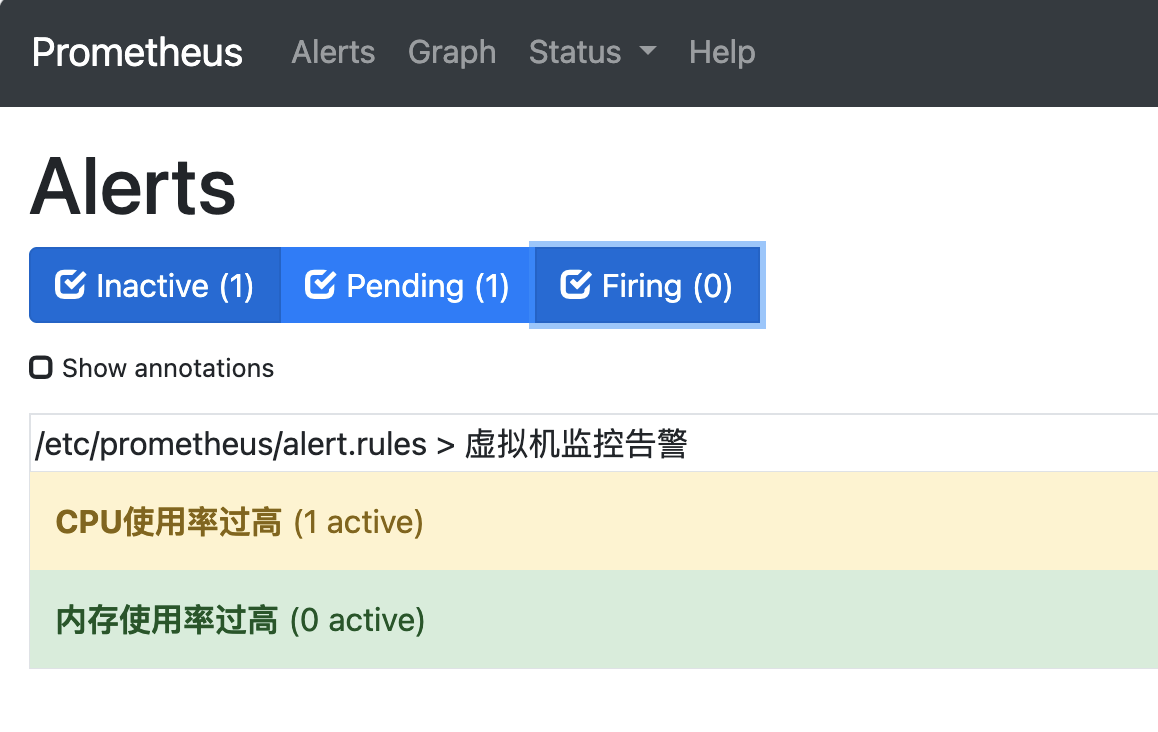
还有一种警告是黄色:
这个的含义就是 : 指标刚超过阈值,但还没到设置的 for: 1m 等待时间
总结:
快递员(Node Exporter)收集数据 Node Exporter 安装在你的服务器上,相当于 “常驻快递员”
它会每 15 秒去服务器里,查一次 CPU 的使用情况,比如 “当前 CPU 用了 90%”。
它把这个数据打包成一个 “快递”,送到
http://你的IP:9100/metrics这个地址,等着 Prometheus 来取
监控室(Prometheus)定时收快递
Prometheus 配置文件里写了
scrape_interval: 15s,意思是 “每 15 秒去收一次快递”。它会每 15 秒去
http://你的IP:9100/metrics取一次 Node Exporter 送来的数据,然后存到自己的数据库里。我们写的
expr: 100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) > 80这行代码,就是 Prometheus 用来计算 “CPU 使用率” 的公式,它会把收到的原始数据,转换成我们能看懂的 “百分比”。
监控室对照 检查清单(alert.rules)检查数据
Prometheus 会按照你写的规则,持续检查计算出来的 CPU 使用率:
a.第一次发现 CPU 使用率是 90%,超过了 80% 的阈值 -> 标记为 Pending(黄色,等待确认)。
b.持续检查,发现 1 分钟内,CPU 使用率一直都在 80% 以上 -> 触发 for: 1m 的条件,标记为 Firing(红色,已触发告警)。
同时,Prometheus 会把这个 “CPU 异常” 的消息,发给 Alertmanager
报警器(Alertmanager)给你发提醒
Alertmanager 收到消息后,会按照你在
alertmanager.yml里配置的邮箱信息,给你发邮件。你在 Prometheus 的
Alerts页面,就能看到这条告警变成了红色的Firing,也就是你图一里看到的样子。